WT32-ETH0 performance analysis using IPerf
In the previous posts, we have been looking at enabling NuttX on the ESP32 based WT32-ETH0 module. In this post, we'll be looking at assessing the performance on the ethernet port, and verify if the ESP32 can really drive traffic up to 100MB/s.
Configuration
The easiest way to get a quick performance assessment of a network device is to use IPerf. Using NuttX, it's so simple- one just need to enable the iperf example under the network utilities within the apps.
Application Configuration --->
Network Utilities --->
[*] iperf example
(eth0) Wi-Fi Network deviceNote that since we will be testing the ethernet port, the "Wi-Fi network device" is changed to eth0.
Also, since performance in critical for this test, we'll get rid of the network traces (aka ninfo) which could seriously impact the performance:
Build Setup --->
Debug Options --->
[] Network Informational OutputAfter flashing, the iperf app is available from the Nutt shell:
nsh> ?
Builtin Apps:
dhcpd dhcpd_stop nsh ping6 sh
dhcpd_start iperf ping renew wapiInitial Testing
So, let's run iperf then - but first with the UDP mode. On the server (the OpenWRT router in my case), this command is used:
iperf -s -p 5471 -i 1 -w 416K -uAnd on the ESP32, the iperf client, this command is used:
iperf -c 192.168.1.1 -p 5471 -i 1 -uAnd that's the result since from the server:
[ 3] local 192.168.1.1 port 5471 connected with 192.168.1.183 port 6184
[ ID] Interval Transfer Bandwidth Jitter Lost/Total Datagrams
[ 3] 0.0- 1.0 sec 3.85 MBytes 32.3 Mbits/sec 0.250 ms 1/ 4035
[ 3] 1.0- 2.0 sec 3.84 MBytes 32.2 Mbits/sec 0.248 ms 0/ 4022
[ 3] 2.0- 3.0 sec 3.84 MBytes 32.2 Mbits/sec 0.248 ms 0/ 4022
[ 3] 3.0- 4.0 sec 3.84 MBytes 32.2 Mbits/sec 0.248 ms 0/ 4023
[ 3] 4.0- 5.0 sec 3.84 MBytes 32.2 Mbits/sec 0.247 ms 0/ 4022
[ 3] 5.0- 6.0 sec 3.84 MBytes 32.2 Mbits/sec 0.248 ms 0/ 4023
[ 3] 6.0- 7.0 sec 3.84 MBytes 32.2 Mbits/sec 0.248 ms 0/ 4023
[ 3] 7.0- 8.0 sec 3.84 MBytes 32.2 Mbits/sec 0.249 ms 0/ 4022
[ 3] 8.0- 9.0 sec 3.84 MBytes 32.2 Mbits/sec 0.248 ms 0/ 4023
[ 3] 9.0-10.0 sec 3.84 MBytes 32.2 Mbits/sec 0.248 ms 0/ 4023
[ 3] 10.0-11.0 sec 3.84 MBytes 32.2 Mbits/sec 0.249 ms 0/ 4023
[ 3] 11.0-12.0 sec 3.84 MBytes 32.2 Mbits/sec 0.248 ms 0/ 4022
[ 3] 12.0-13.0 sec 3.84 MBytes 32.2 Mbits/sec 0.249 ms 0/ 4023
[ 3] 13.0-14.0 sec 3.84 MBytes 32.2 Mbits/sec 0.248 ms 0/ 4023
What we are expecting is up to 100Mb/s, and we get 1/3 if it out of the box. Not bad! But let's try to find if there any configuration which could be updated to improve the performance - before taking this initial result as granted.
Reverse Engineering the performance
Inside the iPerf client
The code used for the iperf client in UDP mode is quite simple. Here is its pseudo code:
static int iperf_run_udp_client(void)
{
sockfd = socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP);
setsockopt(sockfd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt));
addr.sin_family = AF_INET;
addr.sin_port = htons(s_iperf_ctrl.cfg.dport);
addr.sin_addr.s_addr = s_iperf_ctrl.cfg.dip;
buffer = s_iperf_ctrl.buffer;
udp = (struct iperf_udp_pkt_t *)buffer;
want_send = s_iperf_ctrl.buffer_len;
while (!s_iperf_ctrl.finish)
{
actual_send = sendto(sockfd, buffer, want_send, 0,
(struct sockaddr *)&addr, sizeof(addr));
if (actual_send == want_send)
{
s_iperf_ctrl.total_len += actual_send;
}
else
{
.... handle the error ...
}
}
}So, just call "sendto" as fast as possible! What we have here is a standard producer consumer, where the producer is the above code calling the blocking sendto function, and the consumer the ethernet device consuming data via its DMA interface.
Inside the ESP32 hardware
The way the DMA interface to the PHY works is explained in the diagram below (based on spec sheet for the ESP32 and LX7).
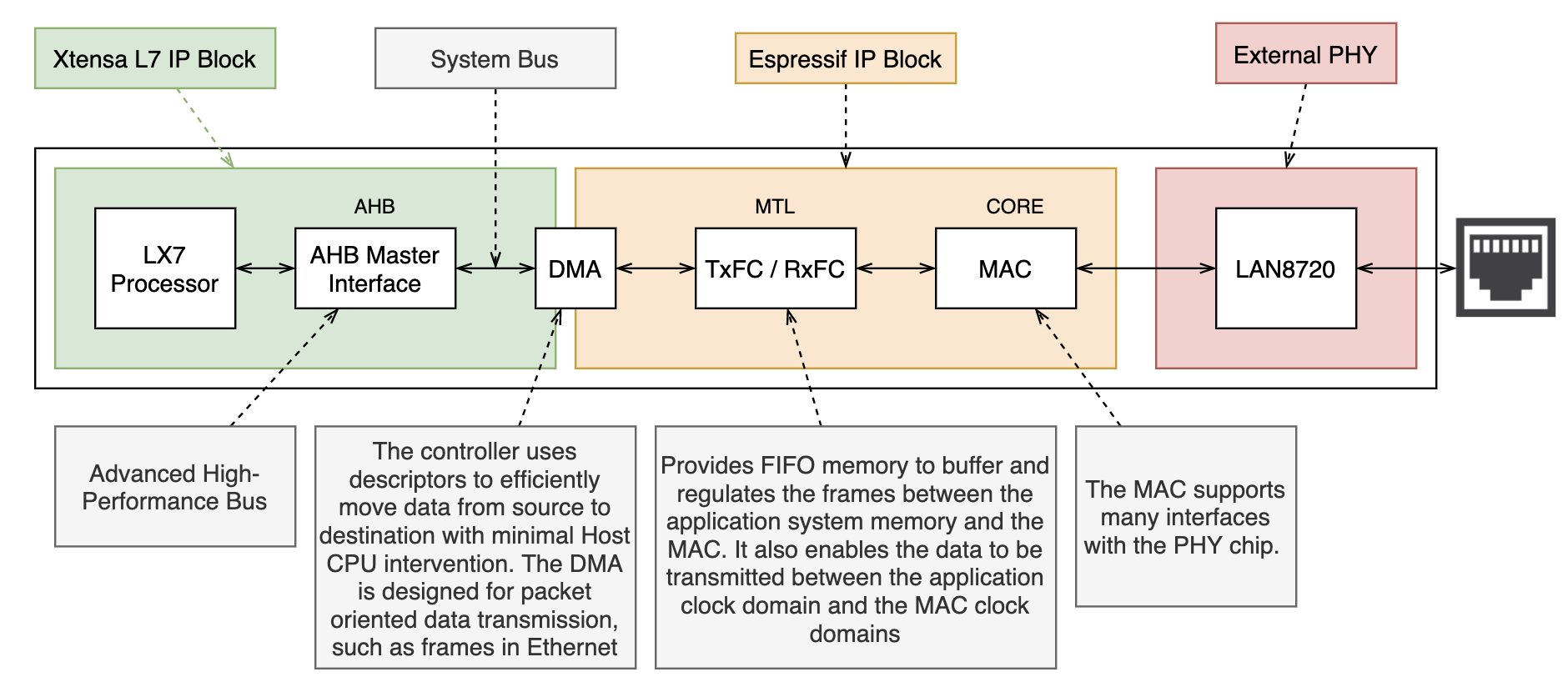
Note that in the case of the WT32-ETH01, the PHY is a LAN8720A from microchip, but there could be any other kind of PHY up to 100Mb/s.
From the ESP32 spec sheet in the Ethernet DMA Features
The DMA has independent Transmit and Receive engines (...) space. The Transmit engine transfers data from the system memory to the device port (MTL), while the Receive engine transmits data from the device port to the system memory. The controller uses descriptors to efficiently move data from source to destination with minimal Host CPU intervention. The DMA is designed for packet-oriented data transmission, such as frames in Ethernet. The controller can be programmed to interrupt the Host CPU for normal situations, such as the completion of frame transmission or reception, or when errors occur
So, all the ESP32 processor should have to do is to prepare the frames and insert them into the DMA ring controller. Assuming we want to achieve 100Mb/s with 1250 bytes frames, that would require having to prepare 10K packets per second, i.e. 100 microseconds per packet. Since we are using UDP, which is quite lightweight in terms of protocol overhead - only having to compute checksums, that should not be a problem.
Inside the NuttX UDP stack
The call to sendto in the iperf client, eventually leads to the following calls:
sendto-> psock_sendto -> inet_sendto -> psock_udp_sendto The psock_udp_sendto comes is two flavors: The unbuffered one, and the buffered one. By default, the unbuffered one is used, so let's check this one. Here is its pseudo code:
ssize_t psock_udp_sendto(FAR struct socket *psock, FAR const void *buf,
size_t len, int flags, FAR const struct sockaddr *to, socklen_t tolen)
{
FAR struct udp_conn_s *conn;
struct sendto_s state;
int ret;
/* Get the underlying the UDP connection structure. */
conn = (FAR struct udp_conn_s *)psock->s_conn;
/* Assure the the IPv4 destination address maps to a valid MAC
* address in the ARP table.
*/
if (psock->s_domain == PF_INET)
{
FAR const struct sockaddr_in *into =
(FAR const struct sockaddr_in *)to;
in_addr_t destipaddr = into->sin_addr.s_addr;
/* Make sure that the IP address mapping is in the ARP table */
ret = arp_send(destipaddr);
}
/* Initialize the state structure. This is done with the network
* locked because we don't want anything to happen until we are
* ready. */
net_lock();
memset(&state, 0, sizeof(struct sendto_s));
/* This semaphore is used for signaling and, hence, should not have
* priority inheritance enabled. */
nxsem_init(&state.st_sem, 0, 0);
nxsem_set_protocol(&state.st_sem, SEM_PRIO_NONE);
state.st_buflen = len;
state.st_buffer = buf;
state.st_sock = psock;
/* Get the device that will handle the remote packet transfers */
state.st_dev = udp_find_raddr_device(conn);
/* Set up the callback in the connection */
state.st_cb = udp_callback_alloc(state.st_dev, conn);
state.st_cb->flags = (UDP_POLL | NETDEV_DOWN);
state.st_cb->priv = (FAR void *)&state;
state.st_cb->event = sendto_eventhandler;
/* Notify the device driver of the availability of TX data */
netdev_txnotify_dev(state.st_dev);
/* Wait for either the receive to complete or for an error/timeout to
* occur. NOTES: net_timedwait will also terminate if a signal
* is received. */
ret = net_timedwait(&state.st_sem, _SO_TIMEOUT(psock->s_sndtimeo));
/* Make sure that no further events are processed */
udp_callback_free(state.st_dev, conn, state.st_cb);
/* Release the semaphore */
nxsem_destroy(&state.st_sem);
/* Unlock the network and return the result of the sendto()
* operation */
net_unlock();
return ret;
}The call to the next layer is done via the netdev_txnotify_dev which calls the driver emac_txavail callback. There are two things that could be of a concern in this code:
1- Systematic call to arp_send each time a UDP frame needs to be sent. Fortunately, the arp code is pretty optimised with an ARP cache, so the ARP frame will only be sent once. Even with this cache, it is still possible to optimize the overhead due the arp_send call by replacing arp_send(destipaddr) with arp_lookup(destipaddr)?0:arp_send(destipaddr);, but that does not give more than 3Mb/s improvement - so nothing serious to be considered right now.
2- Systematic call to net_lock and net_unlock while waiting for the frame to be sent. This means that, provided this function is the bottleneck in the UDP performance, it would not possible to use concurrent clients to improve the performance since each client would be sequentially scheduled.
Inside the NuttX network driver
The two functions in psock_udp_sendto which trigger the actual frame transmission:
netdev_txnotify_dev(state.st_dev);
net_timedwait(&state.st_sem, _SO_TIMEOUT(psock->s_sndtimeo));
The first one (netdev_txnotify_dev) lets the driver know that some TX work is pending - what happens in practice is that the driver notifies the kernel worker queue (via work_queue) that works has to be done - and this work will be executed on the specific kernel worker task. There are two tasks, a low and high priority one, and the network is using the low priority one. This comment in the NuttX code explains why using the high priority queue for the network task is wrong:
NOTE: However, the network should NEVER run on the high priority work queue! That queue is intended only to service short back end interrupt processing that never suspends. Suspending the high priority work queue may bring the system to its knees!
The second function (net_timedwait) waits for the first one to be scheduled and executed. What happens behind the scene is a smart "net_lock" manipulation allowing the TX worker, also waiting on the lock, to be executed "synchronously":
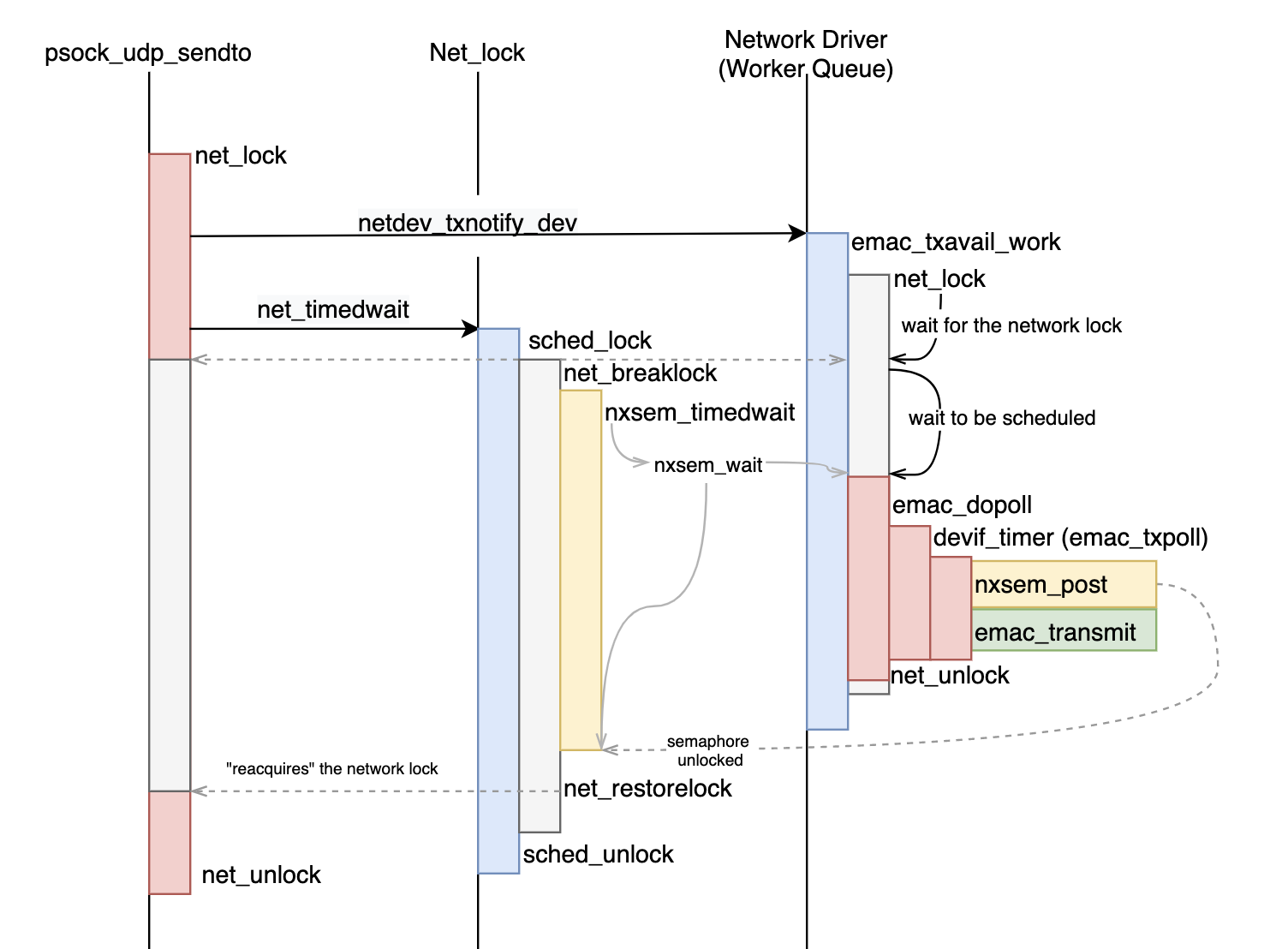
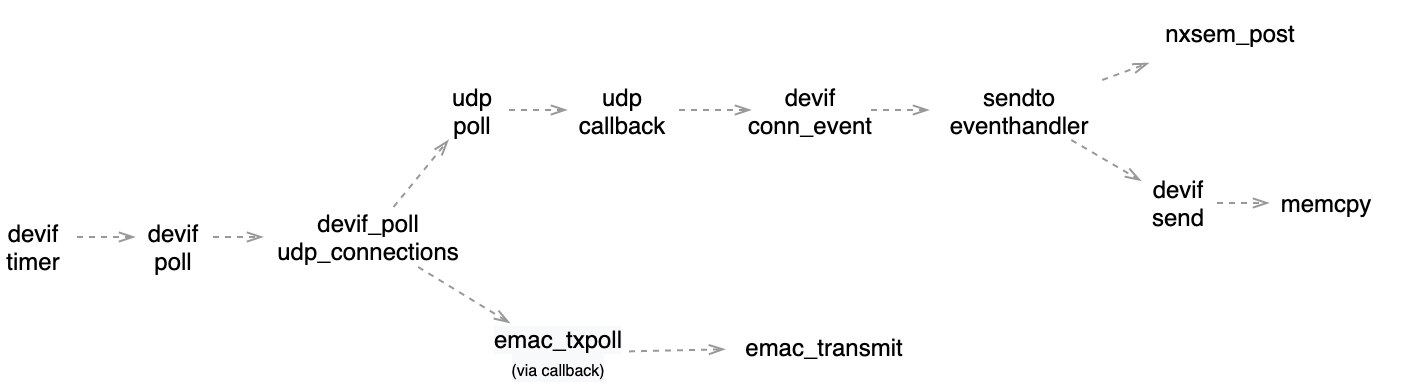
What the above diagram does not explain is the complexity of the devif_timer - which actually calls the callback sendto_eventhandler defined in the psock_udp_sendto function, and then calls the emac_txpoll which eventually starts the DMA via emac_transmit.
There is a small detail in the net_timedwait function worth commenting about: It is that it disables both interrupts (via enter_critical_section ) and the addition of any new task in the to be scheduled list (via sched_lock) . Then, when the semaphore is actually locked (via nxsem_wait), the next likely to be scheduled task in the kernel worker. This way, the scheduling overhead should be limited.
Conclusions
That was a quick deep dive into the NuttX network architecture, but an interesting one to learn how the network "full-stack" is actually implemented. Yet, there are so many details which were not covered, but there is a real feeling of a solid architecture behind NuttX, and that's something very positive if one would decide to capitalise on NuttX for developing a large application eco-system.
Back to the performance, we did not quite reach the 100Mb/s. So, that will be the objective for the next post - where we will try to implement one of those dumb packet blaster by directly bypassing the network stack and inserting frames directly into the DMA queue. We'll also be looking at the options for micro-performance analysis - to measure the actual time spent by functions - for instance using the ESP32 RSR instruction which provides up to 4 nanosecond accuracy, or with the performance monitor from IDF.
Image credits: https://en.wikipedia.org/wiki/Speed_limits_by_country